
- Method 1: Machine learning classification
- Challenge 1: Classifiers can’t generalise across generators
- Challenge 2: The statistical gap is closing
- Method 2: Explicit declaration
- The shared limit of the Explicit Declaration method
- Limit 1: Edits that bypass declaration systems
- Limit 2: No declaration, no signal
- Method 3: Forensic analysis
- Signal 1: C2PA provenance validation
- Signal 2: High-pass filter residual
- Signal 3: Wavelet high-frequency energy ratio
- Signal 4: NSS Benford analysis
- Signal 5: Error level analysis
- Why signal independence matters
- Where forensic detection has limits
- Coming soon: C2PA cryptographic chain verification
- Try it on any image
- The honest picture
If you have uploaded anything to LinkedIn recently, you may have noticed a small “cr” badge appearing in the corner of certain images. That is a Content Credentials marker — click it and LinkedIn shows you the provenance data embedded in the file: which tool created it, whether it was declared as AI-generated, and a cryptographic signature confirming the record has not been altered. Meta applies “Made with AI” and “AI Info” labels on Facebook and Instagram through automated metadata detection. YouTube requires creators to manually disclose AI-generated or realistically altered content during upload, and is adding automated detection alongside that. X shows a “Made with AI” label when creators voluntarily disclose it — and automatically watermarks images generated through its own built-in Grok chatbot.
- Method 1: Machine learning classification
- Challenge 1: Classifiers can’t generalise across generators
- Challenge 2: The statistical gap is closing
- Method 2: Explicit declaration
- The shared limit of the Explicit Declaration method
- Limit 1: Edits that bypass declaration systems
- Limit 2: No declaration, no signal
- Method 3: Forensic analysis
- Signal 1: C2PA provenance validation
- Signal 2: High-pass filter residual
- Signal 3: Wavelet high-frequency energy ratio
- Signal 4: NSS Benford analysis
- Signal 5: Error level analysis
- Why signal independence matters
- Where forensic detection has limits
- Coming soon: C2PA cryptographic chain verification
- Try it on any image
- The honest picture
These systems differ in how they work: some read signals embedded in the file, some rely on the creator’s honesty, some do both. What they share is a common limit. And understanding that limit is what the rest of this article is about.
There are three distinct methods now available for identifying AI-generated images. This article introduces the framework, then goes deep on the method that works even when the others have nothing to work with.

Method 1: Machine learning classification
The first approach is machine learning: train a model on a dataset of known AI-generated and camera-captured images, run new images through it, and hope the model generalises. This is how most “AI detector” tools work — and it is why they fail.
Challenge 1: Classifiers can’t generalise across generators
The fundamental problem is the arms race. Every new image generator produces output with different statistical characteristics. A classifier trained on images from one generator has learned that generator’s artefacts — not the general properties of AI generation. When a new generator ships, or when an existing generator is updated, the classifier has no reliable basis for its conclusions.
Post-processing compounds this. Light JPEG compression, a small crop, a subtle colour grade — any of these can destroy the low-level artefacts a classifier has learned to look for, while leaving the image visually unchanged. The classifier sees a clean image; the image is still AI-generated.
ML-based detection will always lag the generators that produce the content it is trying to detect. It is not a question of whether a specific tool fails — it is a question of when.
Challenge 2: The statistical gap is closing
What makes this trajectory particularly serious is where AI generation is heading. Each generation of models produces output that is measurably more realistic than the last — not just to the human eye, but statistically. The early markers that made AI images identifiable — characteristic smoothness, unusual symmetry, anatomical errors — are being trained away with each iteration. The volume of AI-generated content is growing at the same time as the quality ceiling rises, which means the detection problem is getting harder in both directions simultaneously.
More significantly: the forensic signals that distinguish AI-generated images from camera captures are, in principle, measurable by a machine. Sensor noise distributions, DCT coefficient statistics, high-frequency energy ratios — these are all quantifiable. A sufficiently sophisticated generator could be trained to reproduce them. We are not at the point where generators reliably mimic the natural imperfections of a camera sensor. But the direction is clear. The same analytical techniques that make forensic detection possible today are the training targets for tomorrow’s generators. That is the long-term challenge, and it is worth being honest about it upfront.
Method 2: Explicit declaration
The second approach is explicit declaration — the content itself signals its AI origin. This takes three forms in practice.
Platform visual labels. The implementation varies considerably by platform:
- LinkedIn reads C2PA metadata embedded by the creating tool and displays a “cr” (Content Credentials) badge in the corner of the image. Clicking the badge opens a provenance panel showing what tool created the file and what it declared. Detection is fully automated — no action required from the person posting.
- Meta (Facebook and Instagram) applies “Made with AI” or “AI Info” labels through automated metadata detection. The system reads both C2PA signals and platform-specific watermarks, and is sensitive enough to catch minor AI edits — not just fully AI-generated images. A self-disclosure toggle is also available during upload for cases where creators want to declare AI use proactively.
- YouTube operates primarily on creator disclosure. When uploading content that uses realistic AI-generated or synthetically altered material — placing a real person in a fabricated scene, generating a realistic voice — creators are required to check a disclosure box. The label appears beneath long-form videos or as an overlay on Shorts. YouTube is adding automated detection alongside this, but the disclosure requirement is the primary mechanism.
- X (formerly Twitter) provides a “Made with AI” toggle on the post-compose screen for voluntary disclosure. Images generated directly inside X using its Grok chatbot are automatically watermarked by the platform itself.
C2PA metadata. The Coalition for Content Provenance and Authenticity (C2PA) is the open standard underlying LinkedIn’s badge and much of Meta’s automated detection. A C2PA-signed manifest embedded in the file can carry a digitalSourceType assertion explicitly declaring the content as trainedAlgorithmicMedia (fully AI-generated) or compositeWithTrainedAlgorithmicMedia (AI-edited photograph). The manifest is cryptographically signed — verifiable without contacting the signer. I covered how the signing chain works, what it proves, and where it stops in the previous article on C2PA content credentials.
Digital watermarking. Invisible watermarks can be embedded into AI-generated images at the moment of generation — imperceptible to the human eye but detectable by the issuer’s verifier. Google’s SynthID system, used in Gemini-generated images, is the most widely deployed example. The watermark survives JPEG compression, cropping, and many common post-processing operations. Midjourney, Adobe Firefly, and Meta’s image generators have their own watermarking systems. Unlike C2PA, these watermarks are not publicly verifiable — only the issuing organisation can confirm them — but they represent a commitment by the generator to embed a permanent declaration at creation time.
The shared limit of the Explicit Declaration method
Across platforms, the implementation differs — LinkedIn is fully automated via C2PA, YouTube relies primarily on creator honesty, X is opt-in except for its own Grok output. But all forms of explicit declaration share the same underlying limit: they require the creator or generator to participate.
Limit 1: Edits that bypass declaration systems
Consider the images that occupy the space between a clean camera capture and a fully AI-generated scene. A real estate photograph where powerlines have been removed by inpainting to present the property more favourably. A holiday photograph where strangers in the background have been quietly erased. A product shot where the original cluttered environment has been replaced with a clean studio background. Each of these involves AI-assisted manipulation of a real photograph. The edit may be minor, the intent may be entirely reasonable, and whether it constitutes a problem depends heavily on context and viewpoint. But when any of these images is presented as an unedited original — in a listing, a legal proceeding, an insurance claim, a news photograph — the transparency question becomes exactly the same as for a fully AI-generated image.
Method 2 does not address this middle ground. Platform disclosure systems are framed around “AI-generated content” as a category; they are not designed to catch the broad class of AI-assisted edits that materially alter what a photograph depicts. A creator who uses an AI inpainting tool to remove powerlines is not going to tick a “Made with AI” disclosure box — and most platform systems would not flag the file either, because the C2PA manifest, if present at all, may only record a minor edit rather than generation from scratch. The transparency gap is widest not at the extremes — a pure camera capture and a fully AI-generated image — but in the increasingly populated middle.
Limit 2: No declaration, no signal
For images with no declaration at all — undeclared AI generation, a stripped manifest, a tool that never participated in any disclosure system — Method 2 has nothing to work with. Three forces conspire to keep this population large.
Platform metadata sanitisation. Social media networks including Instagram, Reddit, and WhatsApp automatically strip embedded metadata during upload — removing EXIF data, GPS information, and camera details, primarily for user privacy and file-size reduction. C2PA manifests and other provenance declarations are typically stored as part of this embedded metadata layer and are erased in the same process — not through any deliberate targeting of provenance data, but as a side effect of general sanitisation. An image that left the creator’s device with a complete provenance record may arrive at its destination with none.
Open-source generation. A significant share of AI-generated images are produced by open-source models — tools that carry no obligation to embed declarations and leave the decision entirely to the person running them. There is no platform watermark here, no automatic label, no opt-in system. If the user does not add a declaration, no one else will.
Manual removal. Visible AI indicators — logos, text overlays, watermarks baked into the image frame — are trivially removed by cropping. Invisible watermarks, which are more robust, can be degraded by aggressive recompression or colour-space conversion. C2PA manifests can be stripped by re-saving the file through any tool that does not write C2PA.
The result is that even images which left their origin with a declaration often arrive at the viewer without one. When Method 2 has a signal, it is the most reliable indicator available. But the absence of a label tells you almost nothing about whether an image is AI-generated. That is where Method 3 begins.
Method 3: Forensic analysis
The third approach examines specific, independently-verifiable signals embedded in the file’s physical structure — signals that have nothing to do with visual appearance and everything to do with how the file was physically made.
The key distinction from Method 1: these signals are not learned from examples of AI-generated images. They are derived from physical and mathematical properties of the encoding process. A camera sensor produces noise through quantum physics; the statistical characteristics of that noise are measurable. A diffusion model produces upsampling artefacts with different statistical characteristics; those too are measurable. The difference between them does not change when a new generator ships. No retraining needed.
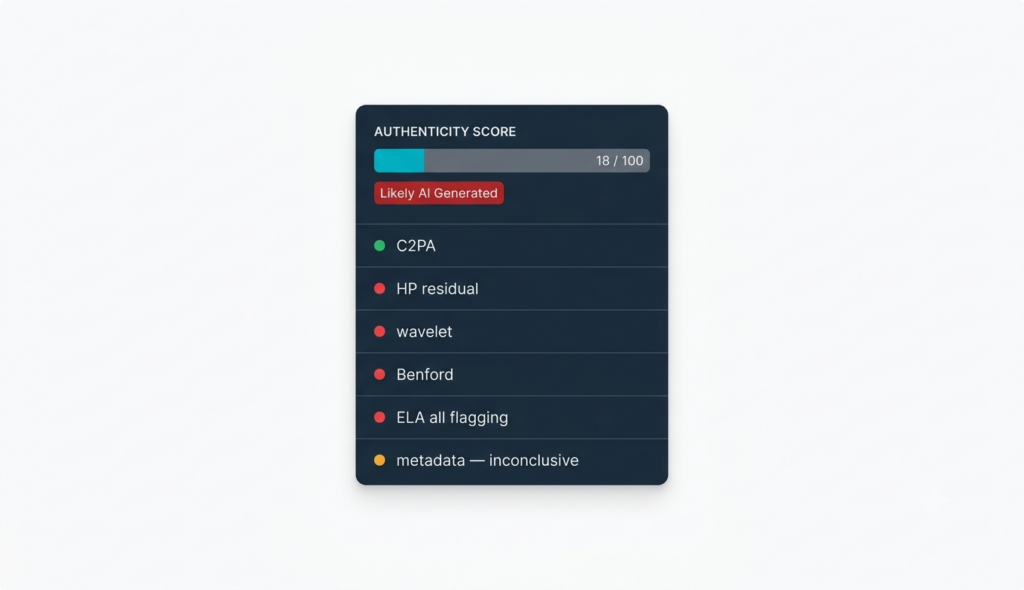
snapWONDERS extracts six of these signals and combines them into a single authenticity assessment. Here is what each one measures and why it works.
Signal 1: C2PA provenance validation
When a C2PA manifest is present, snapWONDERS reads the embedded claims and extracts the digitalSourceType assertion. A manifest declaring trainedAlgorithmicMedia is the highest-confidence finding available — it is a direct declaration from the creating tool itself, embedded in the file’s structure rather than applied as an external label.
When no manifest is present, snapWONDERS notes the absence and proceeds with the remaining signals. Absence of C2PA is not suspicious — most images have none. Full cryptographic chain verification — confirming the signing certificate is genuine and the pixel hash matches the image — is in active development; see the section below.
Signal 2: High-pass filter residual
Camera sensors produce noise through the physics of photon detection — random variation at the pixel level that follows predictable statistical distributions. This noise is always present in a camera capture and always has the same character: fine-grained, spatially uncorrelated, and consistent with the sensor’s known noise model.
AI image generators work through a very different process. Diffusion models iterate by denoising a random field — the upsampling steps introduce structured, periodic artefacts in the high-frequency residual that a camera sensor would never produce. These artefacts are invisible to the human eye but measurable after passing the image through a high-pass filter that isolates the noise floor from the image content.
The residual from a camera capture looks like random noise. The residual from an AI-generated image has structure. That structure is the finding.
Signal 3: Wavelet high-frequency energy ratio
A wavelet decomposition separates an image into sub-bands at different spatial frequencies and orientations. Camera captures contain genuine high-frequency detail — fine texture, edge sharpness, grain — throughout the image. AI-generated images are characteristically smooth in the highest-frequency sub-bands, even when they appear sharp at normal viewing scale. The generative process produces interpolated smoothness where real photographic detail would have micro-texture.
The ratio of energy in the high-frequency sub-bands to the low-frequency sub-bands differs systematically between camera captures and AI-generated images. This ratio reflects the generation process rather than the scene being depicted — a landscape and a portrait will have very different content, but their high-frequency energy distributions follow the same underlying pattern determined by how the image was made. The degree of smoothness varies across generators and model generations, which is why the wavelet ratio functions as a strong statistical indicator rather than a binary rule, and why it is most reliable when read alongside the other signals.
Signal 4: NSS Benford analysis
Benford’s Law is a well-documented mathematical regularity: in many naturally-occurring numerical datasets, the leading digit is not uniformly distributed. The digit 1 appears far more often than 9. This regularity holds for the DCT coefficient distributions in camera-captured JPEG images — a consequence of the natural statistics of photographic scenes.
AI-generated images deviate from this regularity in ways that reflect the synthetic nature of the pixel values. The magnitude of the deviation varies across generators and processing pipelines — some produce more pronounced divergence than others. The value of NSS Benford analysis is as a corroborating signal: when multiple independent measures point in the same direction, the combined finding is far more reliable than any single statistical indicator in isolation.
Signal 5: Error level analysis
Every time a JPEG is saved, the compression introduces a specific level of error relative to the previous version. Error level analysis re-compresses the image at a known quality level and measures the difference. In a camera-captured JPEG saved once, the error distribution is relatively uniform across the image. In an image that has been processed or composited differently in different regions, the error distribution is not uniform — different parts of the image carry different compression histories.
AI-generated images have a compression history that differs structurally from camera captures. They were not produced by a camera sensor encoded through a JPEG pipeline at a single point in time; the generation process introduces different statistical characteristics in how the image data responds to re-compression.
Signal 6: Metadata absence profile
A camera-captured JPEG accumulates metadata through the act of taking a photograph: EXIF fields populated by the camera firmware, a MakerNote block written by the manufacturer, lens data, autofocus state, a sensor calibration signature, a device-specific encoder fingerprint in the DQT block. These fields are not optional — they are written by the hardware and firmware at capture time.
An AI-generated image has none of them. There is no camera, no lens, no sensor, no firmware, no capture event. The absence of these fields — not their presence — is the forensic signal. A file with no MakerNote, no lens serial, no device calibration fields, and a DQT block that matches no known camera encoder was not produced by a camera.
Why signal independence matters
Each of these six signals is derived from a different physical or mathematical property of the image. The high-pass residual measures noise statistics. The wavelet ratio measures frequency-domain energy distribution. The Benford analysis measures DCT coefficient statistics. Error level analysis measures compression history. The metadata profile measures what the hardware wrote at capture time. C2PA measures what the creating tool declared.
None of these signals depends on the others. A file can pass one check and fail another. When multiple independent signals point in the same direction, the combined finding is far more robust than any single signal alone — because the scenarios that could produce a false result in one signal are different from the scenarios that could produce a false result in another.
Where forensic detection has limits
Forensic analysis is not infallible, and claiming otherwise would be dishonest.
Heavy JPEG recompression can destroy the fine-grained signal in the high-pass residual and affect the Benford distribution. A heavily compressed AI-generated image may return an inconclusive result rather than a confident finding. Error level analysis becomes less reliable when an image has been through multiple compression cycles.
Deepfake composites — real photographs with AI-generated or AI-modified regions — present a mixed signal. The authentic regions carry genuine camera characteristics; the modified regions carry AI characteristics. The spatial map of error level analysis and compression inconsistencies becomes the primary signal in these cases, rather than whole-image statistics.
Some findings are genuinely inconclusive. Six signals pointing in different directions, with no clear preponderance, means the image does not yield a confident determination. That is the correct output — not a forced verdict.
Coming soon: C2PA cryptographic chain verification
One significant capability is in active development at snapWONDERS.
At present, when a C2PA manifest is found in a file, the analysis reads and surfaces its declared content: the creating tool, the digitalSourceType assertion, and the claims recorded at generation time. What is not yet verified is the cryptographic chain backing those claims.
A C2PA manifest is signed using COSE (Cryptographic Object Signing and Encryption) with a certificate issued by an authority in the Content Authenticity Initiative trust hierarchy. The manifest also contains a hash of the actual image pixels — the “hard binding.” Full chain verification will confirm three things simultaneously:
- The signing certificate is legitimate and issued by a recognised C2PA authority
- The image pixels have not been modified since the manifest was written
- The manifest has not been stripped from a different file and reattached to this one
That third point is the capability that matters most. A sophisticated actor could take a C2PA manifest from a legitimately-signed authentic photograph and reattach it to a synthetic image. A system that only reads manifest content would see a plausible-looking declaration. Cryptographic verification catches this — because the pixel hash in the manifest would no longer match the image in the file.
When this ships, snapWONDERS will distinguish clearly between two findings that currently look identical from the outside: “manifest present, declares authentic” and “manifest present, declares authentic, signing chain verified, pixel hash confirmed.”
Try it on any image
Every signal described in this article is run automatically by snapWONDERS. Upload any image — camera capture, AI-generated, or suspected composite — and the analysis returns C2PA validation, high-pass residual assessment, wavelet energy ratio, Benford deviation, error level analysis, and a metadata absence profile, combined into a single authenticity score with per-signal findings.
No account required. No software to install. No training data that needs updating when a new generator ships.
The honest picture
LinkedIn’s “cr” badge is real, and it is useful. When it appears, pay attention to it. C2PA is a genuine cryptographic commitment, and SynthID is a genuine technical investment by the organisations embedding it. YouTube’s disclosure requirement and Meta’s automated detection are meaningful steps toward transparency.
But a creator who does not disclose, a tool that embeds no watermark, a platform that strips metadata on upload — none of these surfaces anything through Method 2. The majority of AI-generated images in circulation carry no declaration at all, and many that once did have had it quietly removed in transit.
For those images, the file’s physical structure is the only evidence available. It does not require honesty from anyone.
Kenneth Springer is the founder of snapWONDERS, a digital forensic analysis platform for images and video. The six AI detection signals described in this article — C2PA provenance validation, high-pass filter residual analysis, wavelet high-frequency energy ratio, NSS Benford analysis, error level analysis, and metadata absence profiling — run automatically on every image analysed through the platform and are combined into a single authenticity score. snapWONDERS forensic analysis — no account required.